















Bonree ONE Storage Architecture (ClickHouse-based)
The Bonree ONE is defined by three core principles: lightweight, structured, and precise.
All of these capabilities rely on a stable, reliable, and high-performance data storage foundation.
Currently, Bonree ONE is built on ClickHouse as its core storage engine, supporting multi-domain observability data, including:
APM (Application Performance Monitoring)
RUM (Real User Monitoring)
Logs
Session data
User behavior analytics
Storage Challenges
With multiple integrated modules and highly diverse data scenarios, the underlying storage layer faces several key challenges:
High ingestion throughput: Data volume must scale to PB-level ingestion capacity.
Extreme traffic variability: Workloads exhibit significant peaks and troughs, including sudden traffic spikes.
Complex query patterns: Includes OLAP analytics, raw data queries, and multi-dimensional sorting scenarios.
High query stability requirements: Critical metrics and alert queries must achieve millisecond-level response times.
Complex cluster operations: Including scaling, rebalancing, and data redistribution.
ClickHouse Optimization Strategy
To address these challenges, we optimize ClickHouse across four key dimensions:
write performance, read performance, multi-tenancy, and failover resilience.
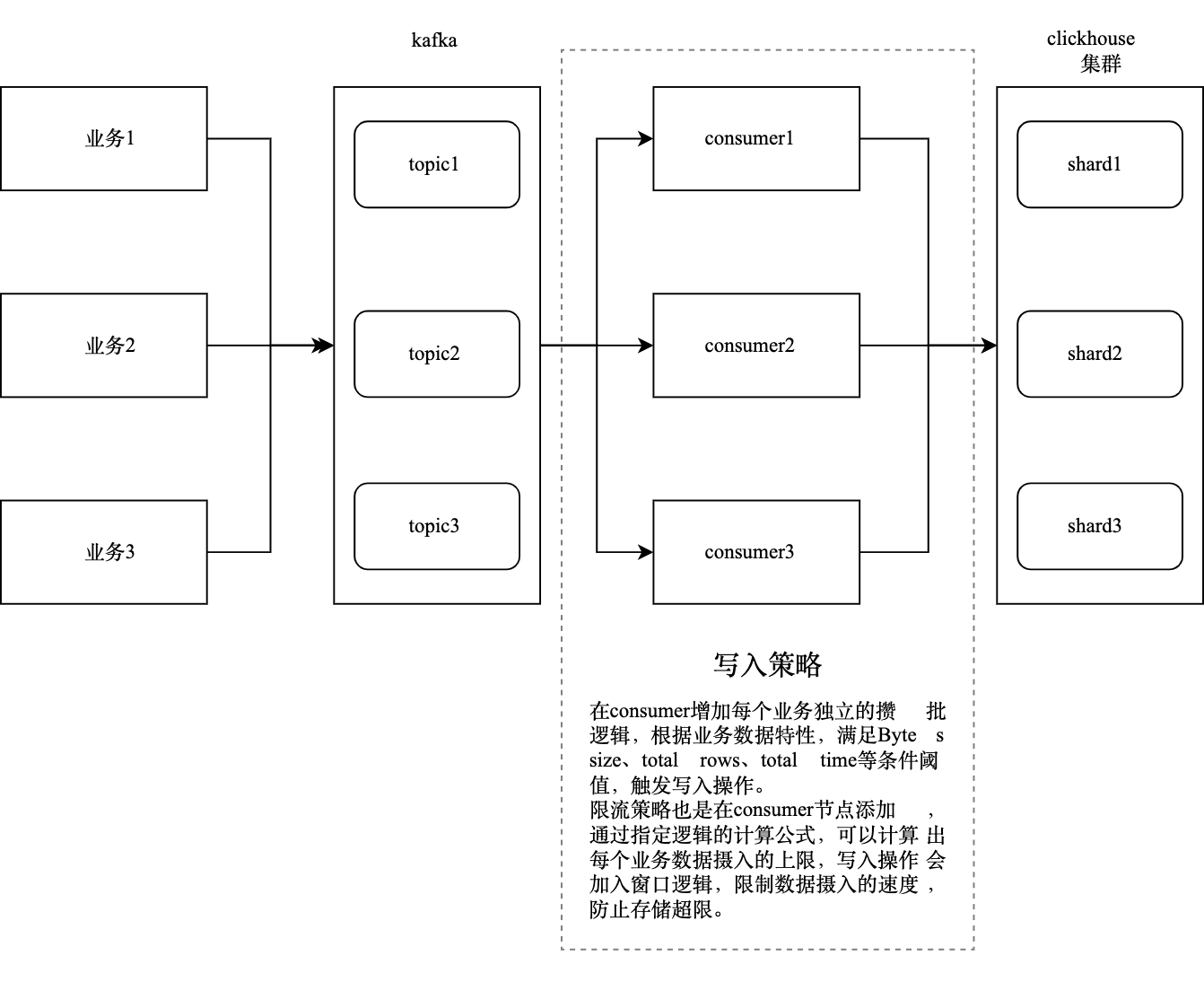
Write Optimization
1. Batch Writing per Table
ClickHouse performs best with batch ingestion, where larger batches significantly improve throughput.
To maximize ingestion efficiency across multiple data scenarios, we introduce a consumer-layer batching mechanism.
Each table is assigned a customized batching strategy, ensuring:
Maximum ingestion throughput on ClickHouse side
Minimal awareness required from upstream business systems
Optimized end-to-end ingestion efficiency
2. Rate Limiting
Under constrained storage resources, ingestion capacity is inherently limited. High ingestion pressure typically comes from two factors:
Excessive total data volume
Sudden ingestion spikes
For sustained overload (high volume), we trigger alerts and address the issue via cluster scaling or data pruning.
For burst traffic scenarios, we implement rate limiting at the consumer layer, ensuring system stability.
Specifically, we introduce a time-window-based control mechanism, including:
Requests per second (QPS) limits
Controlled ingestion intervals
This ensures stable ingestion under peak workloads.
Read Optimization
To support stable and efficient query performance across multiple business domains, we optimize query execution in the following areas:
1. Query Acceleration
OrderBy & Primary Key Design
The
ORDER BYclause defines physical data sorting and is critical for query efficiency.It should align with high-frequency query patterns.
Sorting should follow a progression from low-cardinality to high-cardinality fields.
The PRIMARY KEY is generally aligned with ORDER BY.
If filters do not fully cover all ORDER BY fields, a subset of leading fields can be used as the primary key.
However, the primary key must always be a prefix of the ORDER BY fields.
Indexing Strategy
Bloom Filter index (BFIndex): for equality filtering
MinMax index: for range queries
TokenBF index: for full-text search scenarios
Materialized Views
For fixed and repeatable query patterns, materialized views are used to:
Improve query performance significantly
Maintain data consistency
Reduce computational overhead
Projections
For pre-aggregation scenarios, ClickHouse projections provide:
Higher query efficiency
Automatic query routing
Reduced application-side complexity
2. Compression & Encoding
ClickHouse supports multiple compression algorithms:
NONE: No compression
LZ4: Fast compression
LZ4HC: High compression variant with adjustable level
ZSTD: High-efficiency general-purpose compression
Benchmark results show that ZSTD achieves 5–6x better compression efficiency than LZ4.
Encoding Techniques
To further optimize storage efficiency, ClickHouse provides multiple encoding strategies:
Delta encoding: Stores differences between adjacent values
DoubleDelta encoding: Stores differences of deltas (ideal for time series)
Gorilla encoding: XOR-based compression for slowly changing floating-point values
T64 encoding: Bit-level compression for integer types
FPC encoding: Prediction-based compression for floating-point values
Based on data characteristics:
Time-series fields use DoubleDelta + ZSTD(1)
String fields use ZSTD(1)
3. Fine-Grained Data Types
ClickHouse provides highly granular data types to optimize storage and computation:
Use
Int8 / Int16 / Int32 / Int64appropriatelyPrefer minimal sufficient data types (e.g.,
Int8instead ofInt64)Use
LowCardinality(String)for low-cardinality string fieldsUse
Mapfor semi-structured data where appropriateUse JSON only when necessary
Multi-Tenancy
ClickHouse supports multi-tenant architectures to ensure workload isolation and stable query performance.
In Bonree ONE:
Each product line is assigned a dedicated tenant
Tenant-level resource configuration is customized based on priority and workload characteristics
Although ClickHouse does not provide strict internal resource isolation, we implement:
End-to-end monitoring
Alerting and tracing
Rapid tenant resource release mechanisms
This reduces resource contention and improves system stability under load.
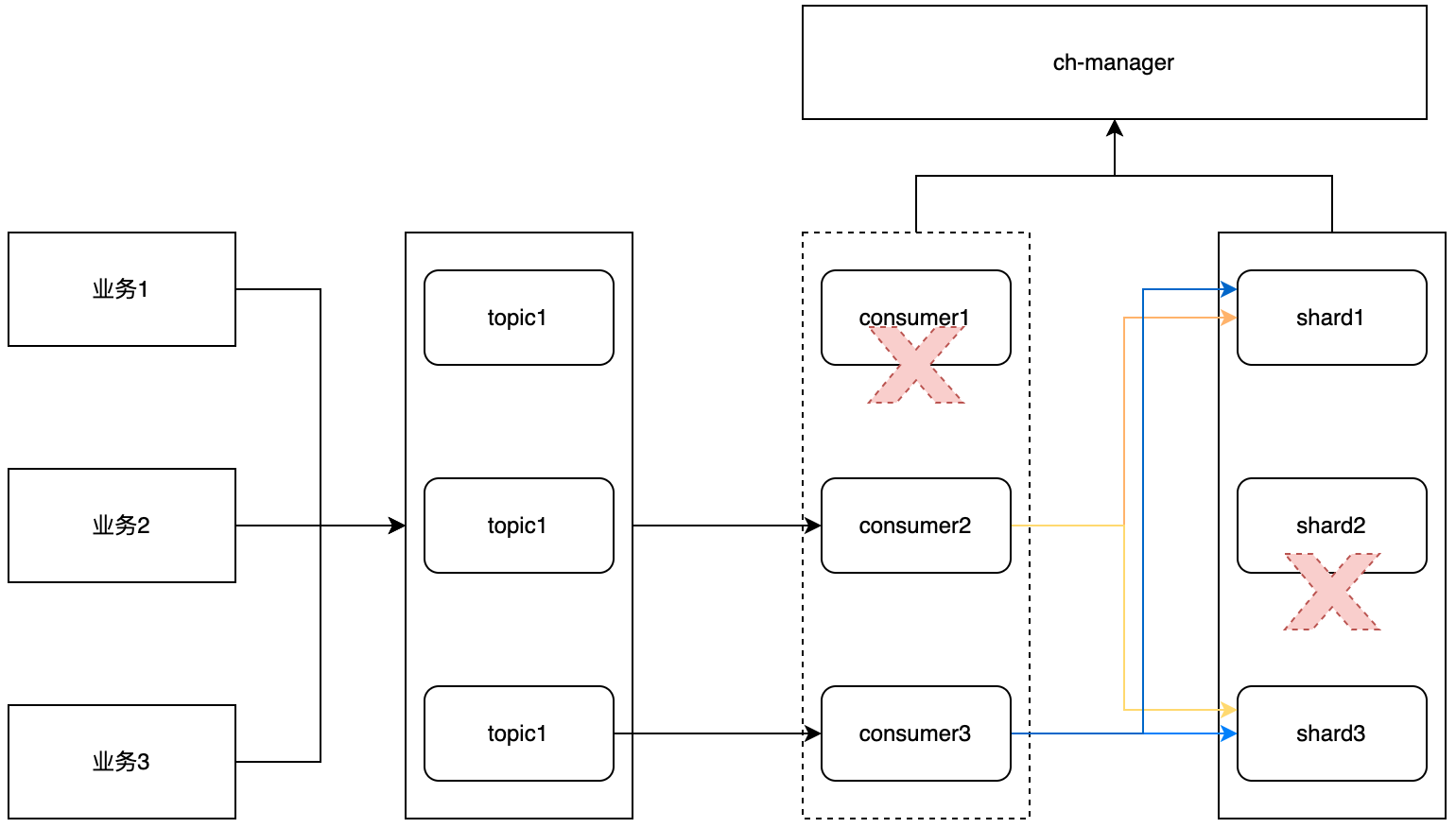
Failover Strategy
To ensure high availability for both ingestion and query paths, Bonree ONE implements a robust failover mechanism.
When either:
Consumer nodes fail, or
ClickHouse nodes experience anomalies
The CH-Manager control layer detects failures and performs traffic rerouting:
Redirects ingestion traffic away from failed nodes
Ensures uninterrupted query services
Adjusts ingestion strategies dynamically
Prevents cascading failures (snowball effects)
Results
Write performance: Latest Bonree ONE version improves ingestion throughput by 3–5x compared to the spring release, with significantly improved stability under peak traffic.
Read performance: In production public cloud environments, ClickHouse query latency achieves sub-second TP99 performance.
System stability:
Single-node failure does not impact cluster-level ingestion or querying
Consumer node failures do not affect overall ingestion continuity