
















For mission-critical systems such as those in securities firms, one question dominates daily operations: “Is there any issue in the business transaction flow?” Bonree ONE breaks this problem into two steps: first, use a Business Observability Topology to visualize the health of business flows at a glance; second, use a three-layer observability framework to investigate issues progressively from high-level symptoms to root causes. Combined with the division of responsibilities between Level 1 and Level 2 operations teams, the entire process becomes clear and actionable.
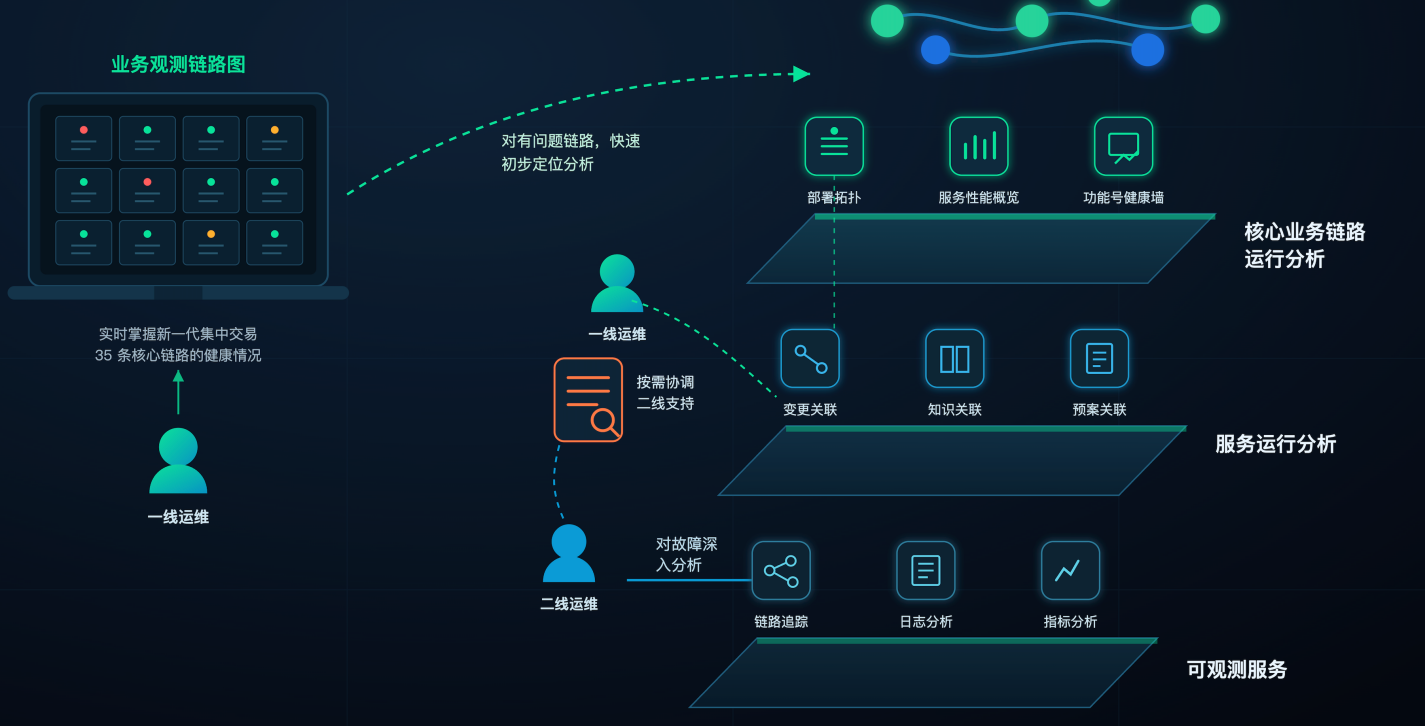
1. Business Observability Topology: Visualizing 35 Business Flows on One Screen
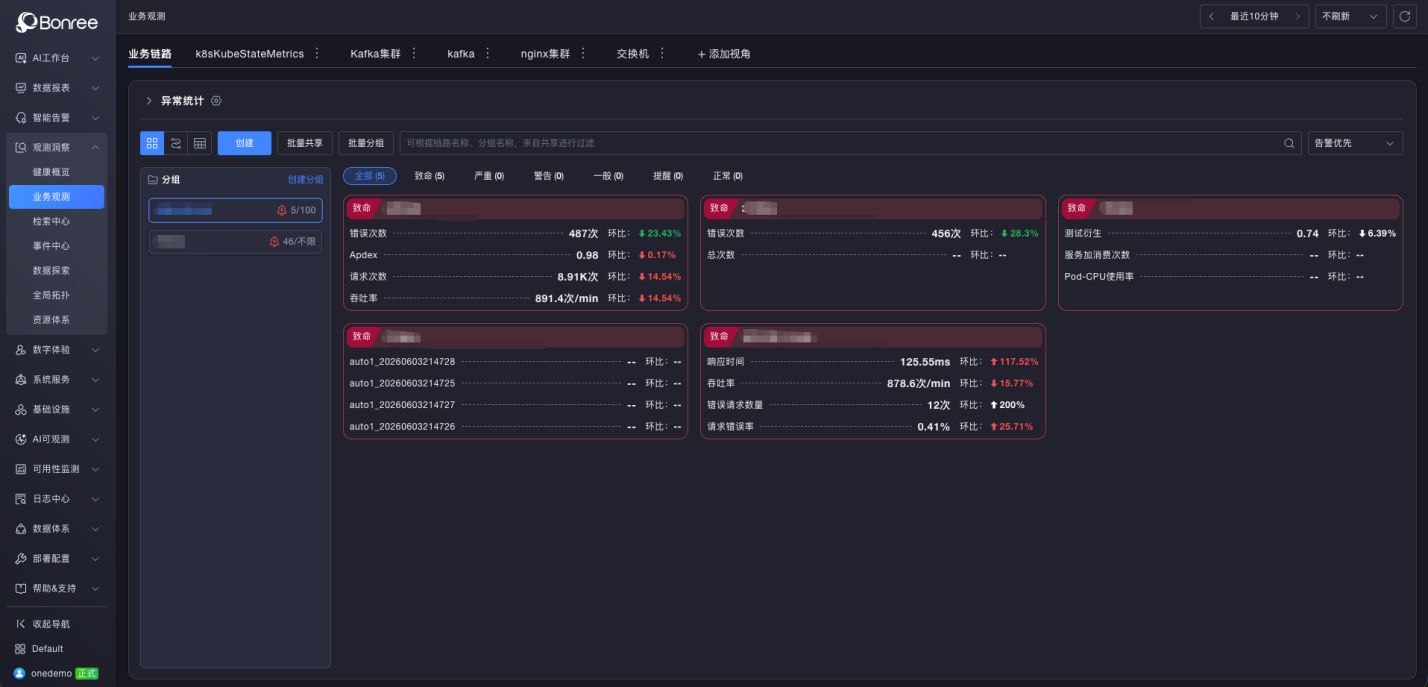
The strength of the Business Observability Topology lies in its intuitive “route map” metaphor. Bonree ONE displays the real-time health status of 35 business transaction flows in the next-generation centralized trading system.
Each business flow is represented as a line.
The red/green status of each node directly reflects its health.
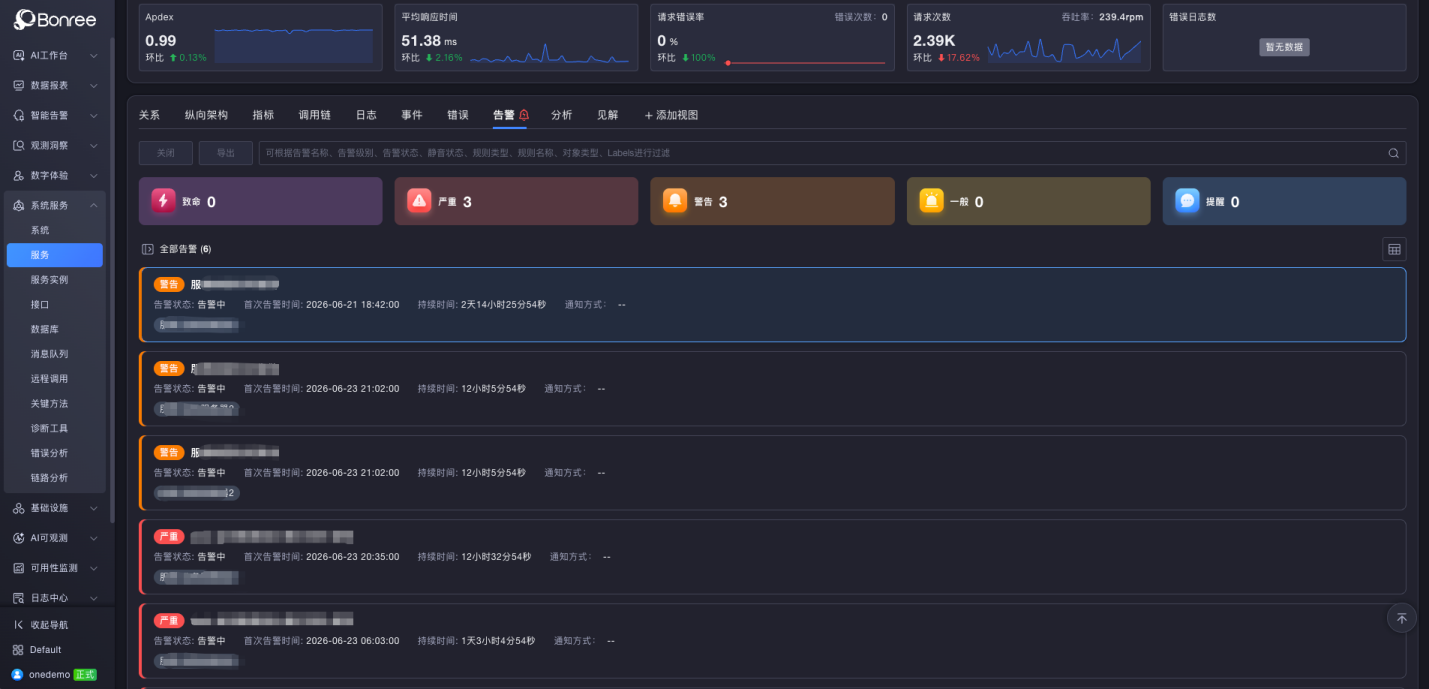
Any flow showing a “red light” becomes immediately visible.
This serves as the primary dashboard for Level 1 operations teams. Before and during trading hours, operators can identify problematic flows within seconds, without waiting for alerts to flood in. Once an abnormal flow is detected, Level 1 teams can perform rapid preliminary analysis and narrow down the affected scope.
2. A Three-Layer Observability Framework: From Symptoms to Root Cause
After a problem is identified in the Business Observability Topology, where should the investigation go next? Bonree ONE organizes its observability capabilities into three progressive layers, with increasingly detailed evidence at each level.
Layer 1
Core Business Flow Analysis
Answering the question: “Is this business flow operating normally overall?”
This layer includes:
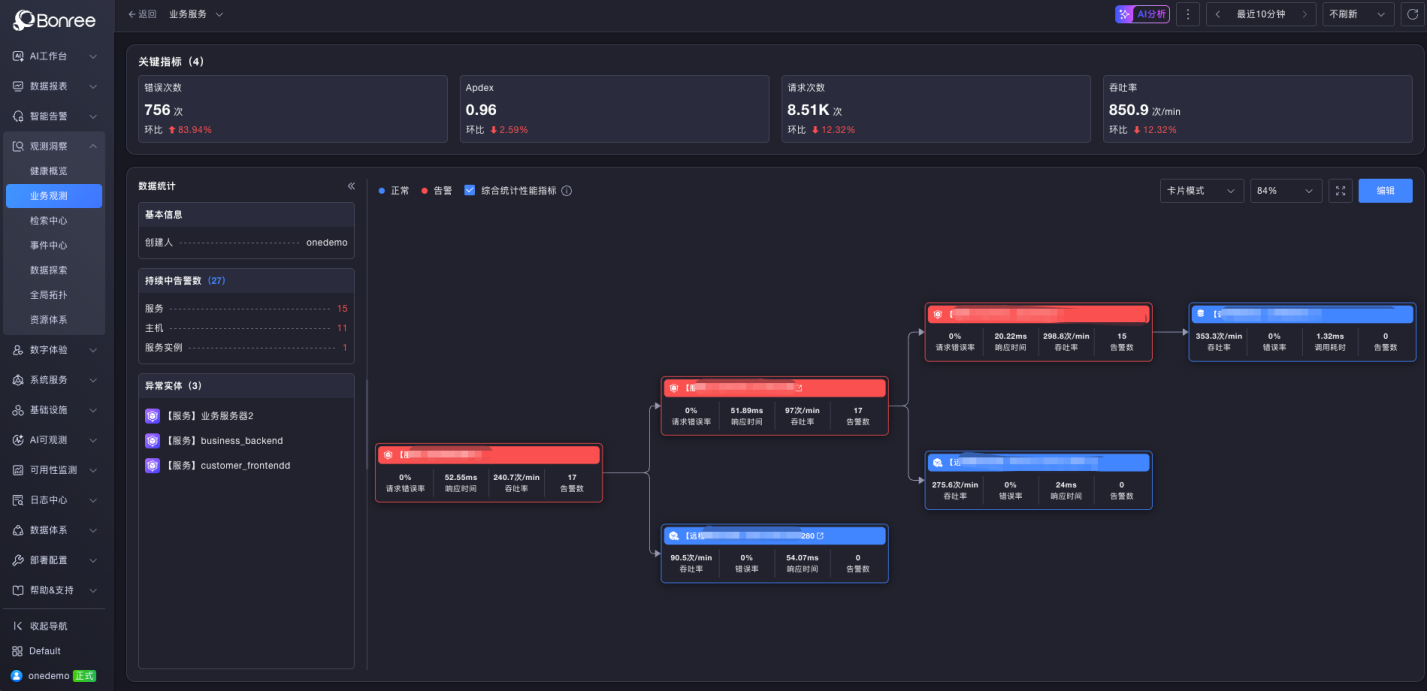
Deployment topology: Which services and nodes make up the flow.
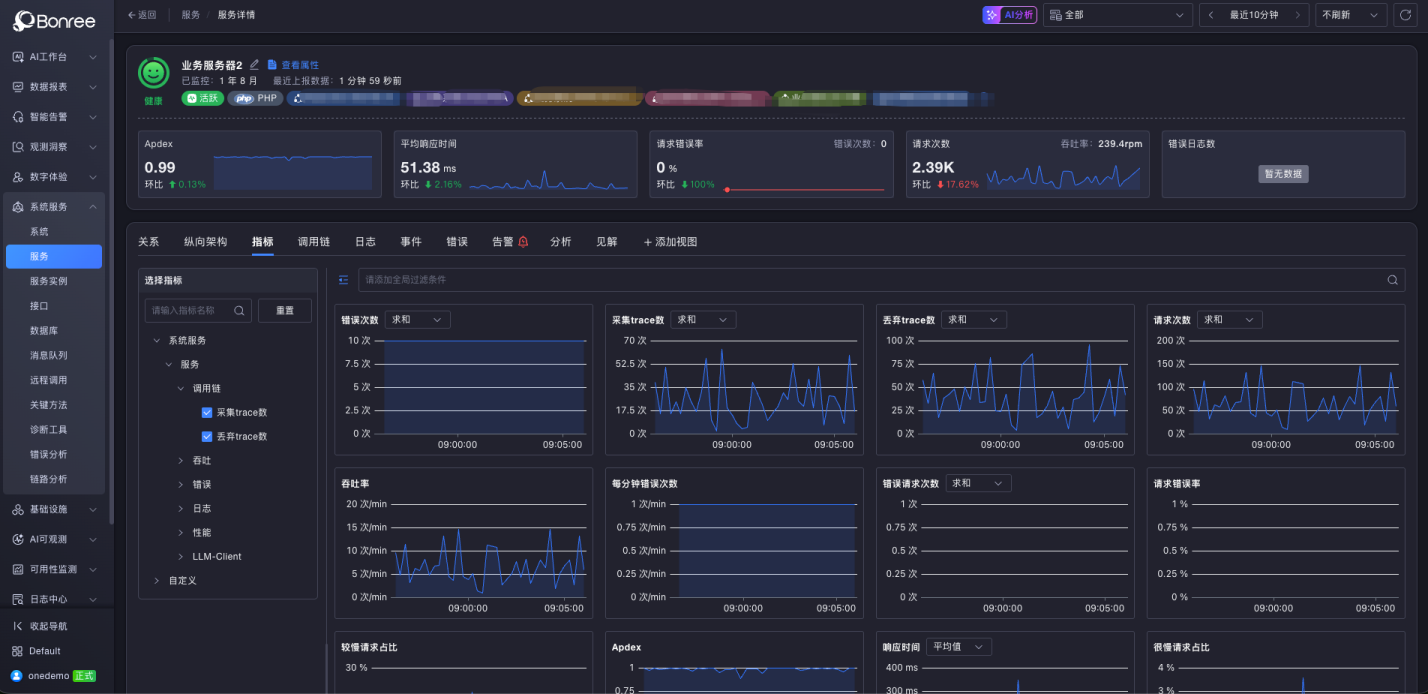
Service performance overview: Key performance indicators in a single view.
Function-level health dashboard: Health status displayed by business function.
By drilling down from the Business Observability Topology into this layer, Level 1 operators can quickly identify which segment of the flow and which service is causing the issue.
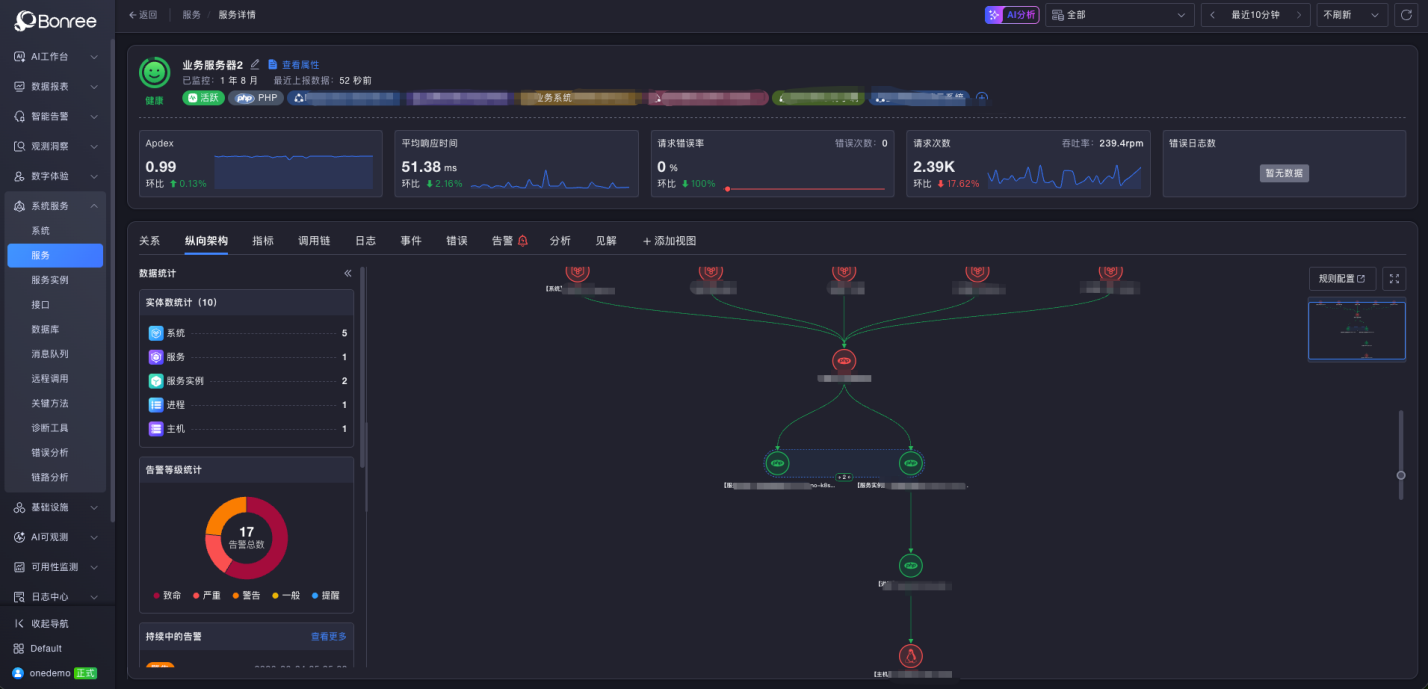
Layer 2
Service Operation Analysis
Answering the question: “Why did this happen, and how was it handled before?”
This layer correlates three critical contexts:
Change correlation: What was recently changed in this flow.
Knowledge correlation: How similar incidents were resolved historically.
Runbook correlation: Whether an existing emergency procedure can be applied.
In many incidents, the answer is hidden in the most recent change. Presenting these contexts together significantly improves troubleshooting efficiency.
Layer 3
Observability Services
Providing the lowest-level evidence for deep root-cause analysis:
Distributed tracing
Log analysis
Metrics analysis
When a problem requires thorough investigation, this layer allows engineers to trace the issue down to specific call chains, log entries, and metric curves, producing definitive conclusions.
3. Summary
In practice, the workflow becomes straightforward:
Level 1 operations monitor the Business Observability Topology. If a business flow turns red, they can identify it within seconds.
By opening Core Business Flow Analysis, they can review the deployment topology and service performance overview to determine which segment and which service is abnormal.
They then check change correlation. In many cases, the root cause is the latest deployment or configuration change, enabling rapid localization.
For truly complex cases that require deep investigation, Level 2 teams continue the analysis through distributed traces, logs, and metrics until they pinpoint the exact call chain and error line.
From “seeing a red light” to “identifying the exact line of failure,” every step is driven by the same topology and the same underlying data. Instead of starting incident response with “everyone, please investigate,” engineers already have concrete entry points and evidence at each stage.
That is the value of Bonree ONE’s three-layer observability framework for mission-critical business flows: turning troubleshooting from reactive firefighting into a structured, evidence-driven process.